


理论应当与时俱进

-
 专利
专利 -
 商标
商标 -
 版权
版权 -
 商业秘密
商业秘密 -
 反不正当竞争
反不正当竞争 -
植物新品种
-
地理标志
-
集成电路布图设计
-
技术合同
-
传统文化
点击展开全部
律师动态
更多 >>


知产速递
更多 >>审判动态
更多 >>案例聚焦
更多 >>法官视点
更多 >>裁判文书
更多 >> 首页
首页专利信息数据中的去重问题研究
字号: +-
563
由于专利具有地域性,在专利检索当中一般都需要在各个国家、组织和地区进行检索,以保证其数据覆盖的全面性,但是由于同族专利等的存在,会导致检索结果中出现重复数据,所以需要去重。去重须建立在每条数据记录有其唯一标识码的基础上,本文首先分析了数据重复的种类,然后提出一种生成标识码的方法,在此基础上按需求进行去重。
专利检索中的数据重复问题
在关于主题的专利检索中,检索人员一般需要在各大国家、组织和地区的检索系统中进行检索,然后对数据进行整合清洗,其工作最基本的就是去重。下文以某条专利数据为例,分别在中华人民共和国国家知识产权局(以下简称SIPO)、美国专利商标局(以下简称US P TO)、欧洲专利局(以下简称EPO)进行检索来具体说明这一问题:
在SIPO的数据库中检索
由于字段较多,只挑选部分来说明数据重复问题,SIPO数据样例见表1。
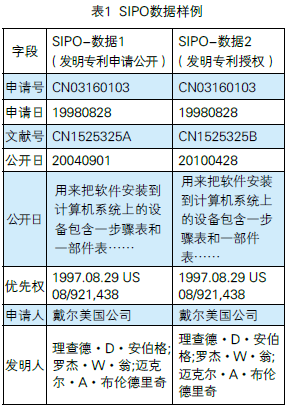
从表1中可以看出:此专利是美国戴尔公司在中国申请的专利,而且在中国已经取得专利权,其生效日期从优先权日1997.08.29开始计算。
在USPTO的数据库中检索
由于专利的地域性,上文提到的专利CN1525325B在USPTO有相关申请,见表2。USPTO在2001前是先发明制的,公开的专利文献即表示对其授予了专利权。
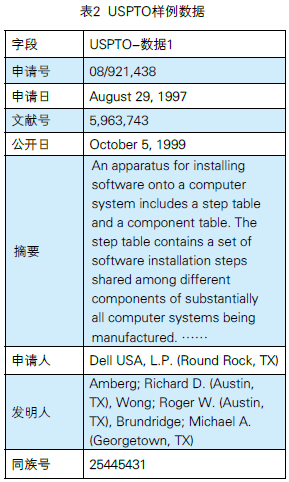
从表2中可以看出:此专利是美国戴尔公司在美国申请的专利,申请人、发明人都与CN1525325B上的信息是一样的。需要说明的是USPTO的记录中多了一个同族号25445431的信息。
在EPO的数据库中检索
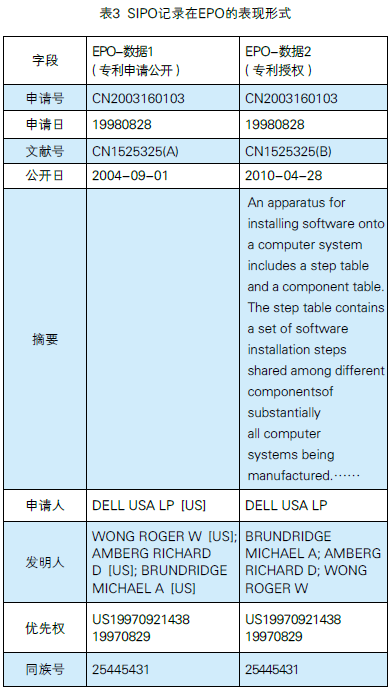
EPO专利信息库的数据收集得较为全面,不仅包含本组织公开的数据,而且还包括其他国家、组织和地区公开的数据,上文提到的CN1525325B数据记录在EPO数据库的表现形式见表3。
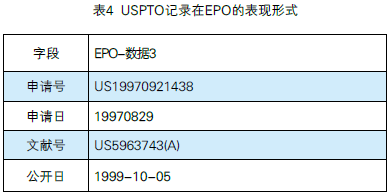
US5963743在EPO数据库的表现形式见表4。

数据重复种类
在分析上文提到的数据后得知,专利数据的重复一般分为三种情况:
第一种情况:申请号、申请日、文献号、公开日相同
此种情况一般是不同语言之间的翻译,需按语言去重。如上文中的SIPO-数据1与EPO-数据1。
第二种情况:申请号、申请日相同
此种情况一般是专利申请的不同阶段, 如CN1525325A属于发明专利申请公开阶段、CN1525325B专利授权阶段,需按国家去重。如上文中的SIPO-数据1与SIPO-数据2。
第三种情况:技术内容相同
此种情况一般是申请人就同一技术主题在不同国家、地区提交专利申请产生的,也就是通常所说的简单同族,需按同族去重。如上文中的EPO-数据1与USPTO-数据1。
实际操作中分析专利分布情况的时候一般要求按照第二种情况进行去重,分析技术要点的时候一般要求按照第三种情况去重。第一种情况主要应用在多语言系统。
文献标识规则及去重方案
根据WIPO标准ST.1--关于唯一化标识专利文献所需最低限度数据元素的建议中提到的内容,只需要文献号、公开日信息就可以唯一确定一篇文献。但是如果需要按国家去重就必须加入申请号、申请日信息。
针对上文提到的数据重复种类提出以下模型,根据专利数据的基本信息,如申请号、申请日、文献号、公开日、公布语言等来生成标识码,在此基础上进行去重。
以表1中的SIPO-数据1为例,对标识码的结构进行说明见表5。
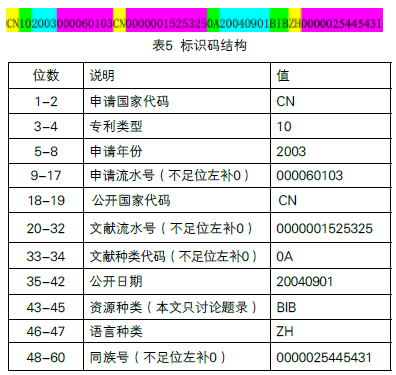
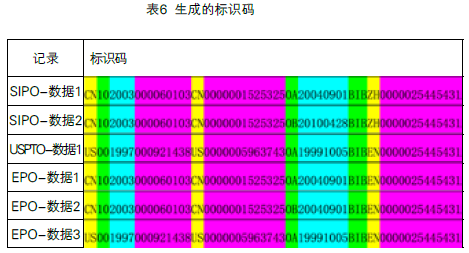
按表5的标识结构规则对上文提到的数据生成标识码见表6。
按语言去重
通过分析数据,我们得知,EPO-数据1、EPO-数据2其实只是SIPO-数据1、SIPO-数据2的翻译,所以SIPO-数据1与EPO-数据1的标识码只有46-47位的语言种类不同、根据标识码的唯一性原则,如果需要中文数据则留SIPO-数据1,需要英文数据则留EPO-数据1。
对于USPTO-数据1与EPO-数据3,其标识码完全相同,根据标识码的唯一性原则,只保留其中一条。
按国家去重
SIPO-数据1与SIPO数据2分别是专利申请的公开信息与授权信息,其标识码只有18-42的文献号、公开日信息不同,如果按国家去重只能保留其中一条,或选公开文献或选授权文献。
按同族去重
表6中所有的数据如果按同族去重的话只能保留一条,其标识码的48-60位都是相同的,如果我们需要中国数据则保留SIPO-数据1或SIPO-数据2,如果需要最早公开的话则保留USPTO-数据1或者EPO-数据3,用户可以自己制定相关规则来确认保留哪条记录。
结语
本文提到的去重方法其核心是生成唯一标识码。此标识码的生成必须建立在对各个国家、组织和地区不同时期的申请号、文献号编码规则清楚了解的基础上,因此,此种方法的具体实施步骤需要长期的分析整理。
此方法可以应用在专利的数据收集、数据交换、数据补充等方面,提高数据质量,从而为向用户提供高质量的专利信息检索报告提供坚实的数据基础。
专利检索中的数据重复问题
在关于主题的专利检索中,检索人员一般需要在各大国家、组织和地区的检索系统中进行检索,然后对数据进行整合清洗,其工作最基本的就是去重。下文以某条专利数据为例,分别在中华人民共和国国家知识产权局(以下简称SIPO)、美国专利商标局(以下简称US P TO)、欧洲专利局(以下简称EPO)进行检索来具体说明这一问题:
在SIPO的数据库中检索
由于字段较多,只挑选部分来说明数据重复问题,SIPO数据样例见表1。
从表1中可以看出:此专利是美国戴尔公司在中国申请的专利,而且在中国已经取得专利权,其生效日期从优先权日1997.08.29开始计算。
在USPTO的数据库中检索
由于专利的地域性,上文提到的专利CN1525325B在USPTO有相关申请,见表2。USPTO在2001前是先发明制的,公开的专利文献即表示对其授予了专利权。
从表2中可以看出:此专利是美国戴尔公司在美国申请的专利,申请人、发明人都与CN1525325B上的信息是一样的。需要说明的是USPTO的记录中多了一个同族号25445431的信息。
在EPO的数据库中检索
EPO专利信息库的数据收集得较为全面,不仅包含本组织公开的数据,而且还包括其他国家、组织和地区公开的数据,上文提到的CN1525325B数据记录在EPO数据库的表现形式见表3。
US5963743在EPO数据库的表现形式见表4。
数据重复种类
在分析上文提到的数据后得知,专利数据的重复一般分为三种情况:
第一种情况:申请号、申请日、文献号、公开日相同
此种情况一般是不同语言之间的翻译,需按语言去重。如上文中的SIPO-数据1与EPO-数据1。
第二种情况:申请号、申请日相同
此种情况一般是专利申请的不同阶段, 如CN1525325A属于发明专利申请公开阶段、CN1525325B专利授权阶段,需按国家去重。如上文中的SIPO-数据1与SIPO-数据2。
第三种情况:技术内容相同
此种情况一般是申请人就同一技术主题在不同国家、地区提交专利申请产生的,也就是通常所说的简单同族,需按同族去重。如上文中的EPO-数据1与USPTO-数据1。
实际操作中分析专利分布情况的时候一般要求按照第二种情况进行去重,分析技术要点的时候一般要求按照第三种情况去重。第一种情况主要应用在多语言系统。
文献标识规则及去重方案
根据WIPO标准ST.1--关于唯一化标识专利文献所需最低限度数据元素的建议中提到的内容,只需要文献号、公开日信息就可以唯一确定一篇文献。但是如果需要按国家去重就必须加入申请号、申请日信息。
针对上文提到的数据重复种类提出以下模型,根据专利数据的基本信息,如申请号、申请日、文献号、公开日、公布语言等来生成标识码,在此基础上进行去重。
以表1中的SIPO-数据1为例,对标识码的结构进行说明见表5。
按表5的标识结构规则对上文提到的数据生成标识码见表6。
按语言去重
通过分析数据,我们得知,EPO-数据1、EPO-数据2其实只是SIPO-数据1、SIPO-数据2的翻译,所以SIPO-数据1与EPO-数据1的标识码只有46-47位的语言种类不同、根据标识码的唯一性原则,如果需要中文数据则留SIPO-数据1,需要英文数据则留EPO-数据1。
对于USPTO-数据1与EPO-数据3,其标识码完全相同,根据标识码的唯一性原则,只保留其中一条。
按国家去重
SIPO-数据1与SIPO数据2分别是专利申请的公开信息与授权信息,其标识码只有18-42的文献号、公开日信息不同,如果按国家去重只能保留其中一条,或选公开文献或选授权文献。
按同族去重
表6中所有的数据如果按同族去重的话只能保留一条,其标识码的48-60位都是相同的,如果我们需要中国数据则保留SIPO-数据1或SIPO-数据2,如果需要最早公开的话则保留USPTO-数据1或者EPO-数据3,用户可以自己制定相关规则来确认保留哪条记录。
结语
本文提到的去重方法其核心是生成唯一标识码。此标识码的生成必须建立在对各个国家、组织和地区不同时期的申请号、文献号编码规则清楚了解的基础上,因此,此种方法的具体实施步骤需要长期的分析整理。
此方法可以应用在专利的数据收集、数据交换、数据补充等方面,提高数据质量,从而为向用户提供高质量的专利信息检索报告提供坚实的数据基础。
 上一篇
上一篇 





评论